https://school.programmers.co.kr/learn/courses/30/lessons/12938
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
답지 안보고 풀었을 때 쾌감이란~
모든 문제가 이렇게 잘 풀렸으면 좋겠다
정말 코테는 종이 없으면 못풀겠다
갤탭씨에게 감사인사를 드립니다.
문제 풀이
{} 집합에 어떤 수가 올지, 몇 개가 올지는 모르지만
조건
집합 안의 수 합이 S가 되는 애들
그리고 집합 수끼리 곱한 수가 최대인 애들을 return 해라
처음에는 {} 집합 안에 있는 수를 주는 줄 알았다.
매개변수를 보니 n 집합 안의 수의 갯수, s 집합 안의 수들의 합
이렇게 두가지만 주어졌다.
집합 안의 수들의 곱이 최대인 애가 답이라서
합해진 S를 찢어서 곱해봤다.
총합S 나누기 집합갯수 를 했을 때 몫이 0보다 작거나 0이면 바로 return -1
나눴을 때 나머지 없이 몫이 떨어지면 간단! [몫, 몫, 몫] 이렇게 몫이 n개 있으면 됐다.
나머지가 있으면 나머지를 처리해야했다. 집합끼리 곱했을 때 최대가 되도록!

(처음에는 n이 2개라고 가정하고 식을 써봤다. 곱한 최대값을 어떻게 비교할지가 막막해서. 그런데 막상 보니까 나머지 없이 잘 나눠떨어지는 애들은 전부 집합이 몫으로 같음. 이걸보니 집합끼리 수 차이가 작을수록 모두 곱했을 때 결과가 크구나가 보였다. 기준을 몫으로 나눠떨어지는 애들 아닌애들로 처리해야함이 보였다.)
<막혔던 부분>
인덱스 초과를 자꾸 시켰다.
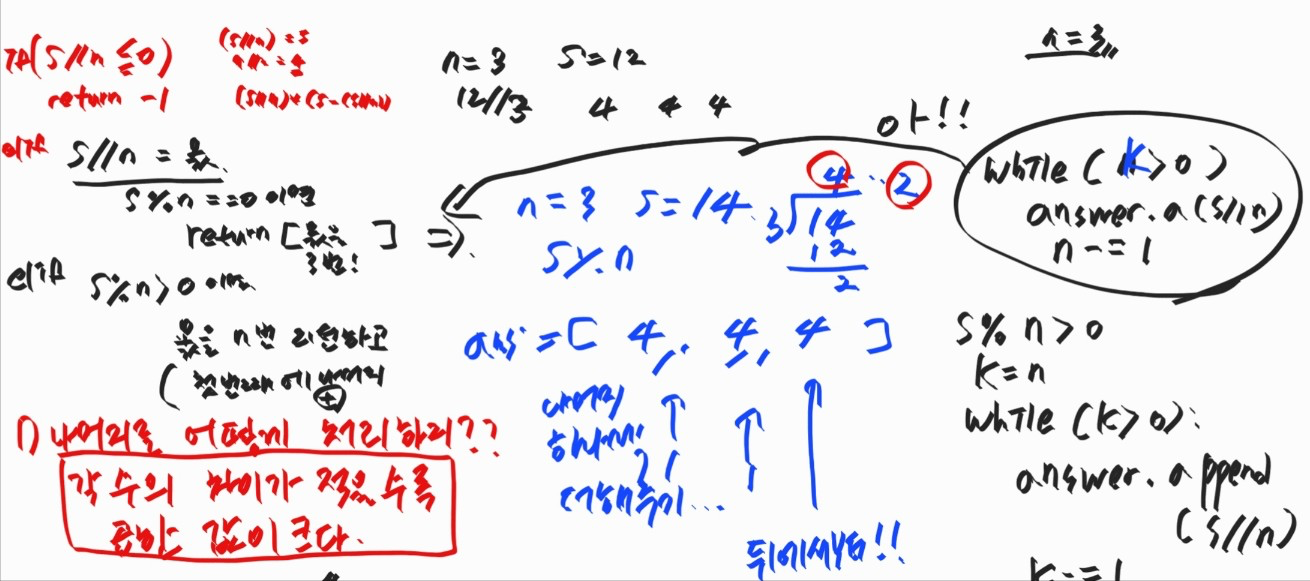
문제1. answer 답 배열에 몫을 n번 저장하면 되는데 n번을 while안에서 1씩 없애주면서 n 반복해서 넣어주었다.
넣는 값을 s//n로 해놔서 n이 값이 변경되었다.
k =n으로 해서 k를 하나씩 빼줬다. 지금 보니 그냥 s//n 몫을 제대로 선언하는게 나을듯
문제2. 아직 answer 에 값 넣지도 않았는데 나머지를 처리한다고 answer[0] = 값을 할당했다. 이렇게 했다. 아직 0번째 값은 없는데.. answer은 빈 배열인데요.. 그리고 답은 (집합의 수는) 작은 수부터 정렬을 원해서 나머지를 뒤에서부터 넣어줘야했다.
나머지를 1씩 쪼개서 맨뒤에서부터 하나씩 더해줬다.
range로 범위정할 때 잘 안돼서 찾아봤다.
my_list = [1, 2, 3, 4, 5]
for i in range(len(my_list) - 1, -1, -1):
print(my_list[i])시작: len(my_list_ -1)
맨 뒤!
범위: -1
맨뒤! 앞에서 조회하는 range와 마찬가지로 범위는 하나 더 한 값으로 써준다. 근데 얘는 마이너스가 붙은.. 맨뒤에서 첫번째까지
스텝: -1
한번 작동할 때마다 인덱스를 1칸씩 이동한다.
결과
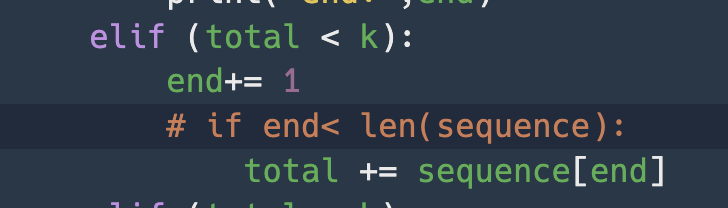
def solution(n, s):
answer = []
max =0
if s//n <=0:
return [-1]
elif s%n ==0:
k = n
while(k>0):
answer.append(s//n)
k -= 1
elif s%n >0:
k = n
while(k>0):
answer.append(s//n)
k-= 1
for i in range( len(answer)-1, len(answer)-s%n-1,-1):
answer[i] += 1
return answer
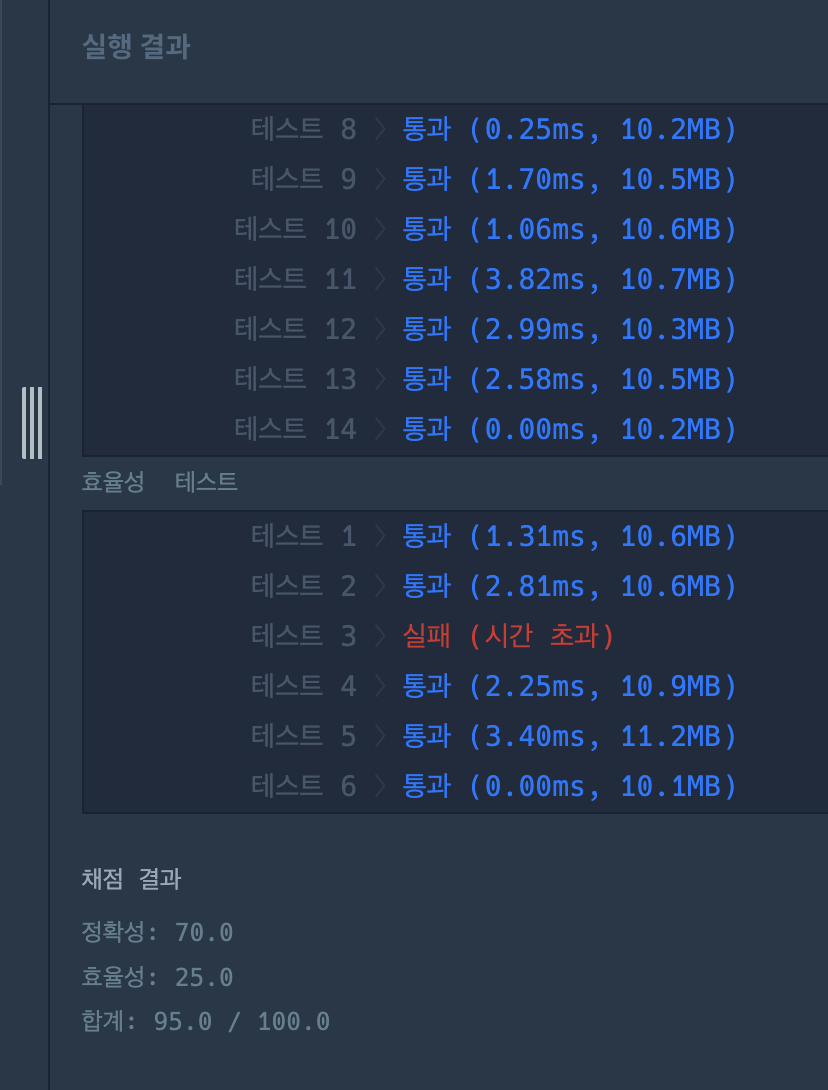
앗!!
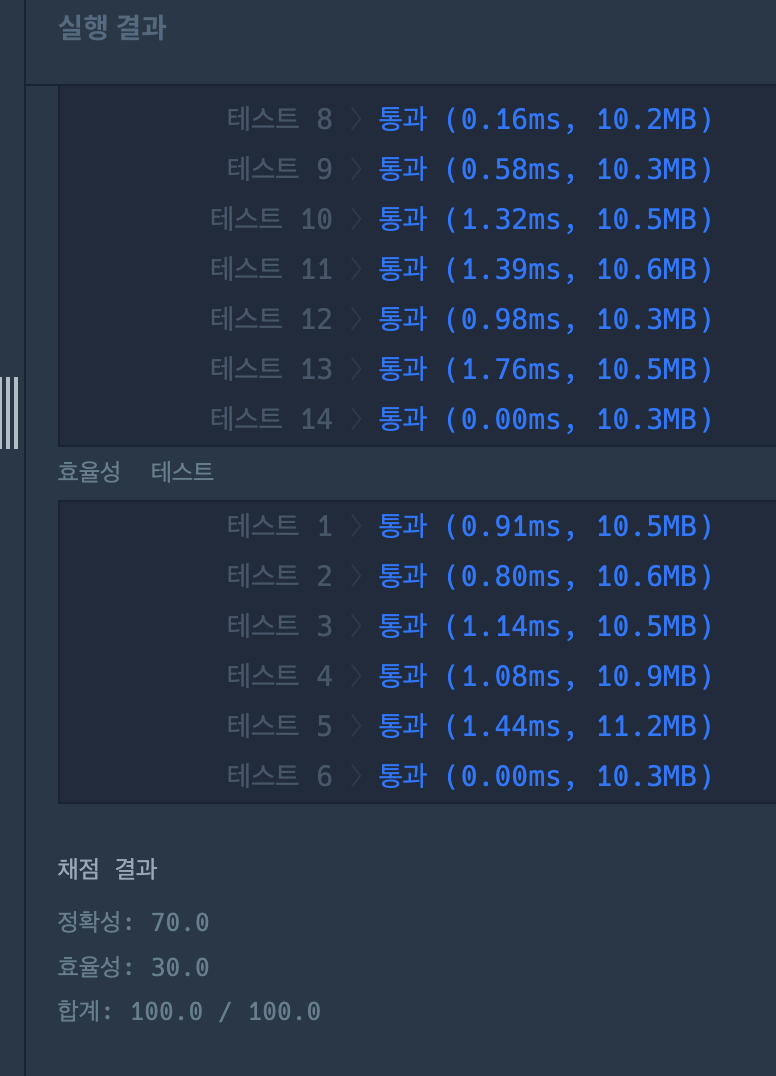
게비스콘~~
시간초과돼서 찾았는데 print 있어서 그랬네 짜슥아~~!!
'코딩테스트 > 프로그래머스' 카테고리의 다른 글
| 프로그래머스 Lv.2 연속된 부분 수열의 합 (0) | 2023.09.06 |
|---|