아래 글은 김영한님의 강의 (스프링DB-1편)으로 공부하고 트랜잭션을 사용해보면서 정리한 내용이다.
트랜잭션 격리수준에 대해서는 ([MySQL] 트랜잭션의 격리 수준(Isolation Level)에 대해 쉽고 완벽하게 이해하기 )블로그를 보았다.
Transaction 어노테이션이 없어도 동작되는 이유가 뭐지?
이 어노테이션은 언제 사용해야하는가?
이런 질문에 대한 답을 구하기 전에
먼저 트랜잭션 개념에 대한 정리가 필요했다.
트랜잭션
- 트랜잭션은 무엇인가?
- 트랜잭션 : 거래
- 트랜잭션은 이런 데이터 상의 거래를 안전하게 처리하고 보장해준다.
- 트랜잭션 ACID:
-
- 원자성 (Atomicity):
- 예시: 은행 계좌 이체
- 고객이 A 계좌에서 B 계좌로 일정 금액을 이체하는 트랜잭션을 고려하면, 이체 작업은 A 계좌에서의 출금과 B 계좌로의 입금 두 단계로 이루어진다. 이 두 단계는 원자성을 가져야 하며, 하나의 단계가 실패하면 다른 단계도 롤백되어야한다.
- 일관성 (Consistency):
- 예시: 주문 및 재고 관리
- 상품 주문 트랜잭션에서는 주문이 들어올 때마다 재고가 감소해야 한다. 이때 주문 트랜잭션이 성공하면 재고가 감소하고, 실패하면 재고는 변하지 않아야 한다. 이를 통해 데이터베이스는 일관된 상태를 유지한다.
- 격리성(고립성) (Isolation):
- 예시: 동시 계좌 이체
- 여러 사용자가 동시에 계좌 간 이체를 시도하는 상황에서, 각각의 트랜잭션이 다른 트랜잭션에 영향을 주지 않아야 한다. A 계좌에서의 이체 작업이 완료되기 전까지는 B 계좌에서의 이체 작업을 다른 트랜잭션이 간섭하지 않도록 보장되어야 한다.
- 격리성은 동시성과 관련된 성능 이슈로 인해 트랜잭션 격리 수준(Isolation level)을 선택할 수 있다.
- 지속성 (Durability):
- 예시: 주문 정보의 저장
- 고객이 주문을 완료하면 해당 주문 정보는 데이터베이스에 영구적으로 저장되어야 한다. 시스템 장애 또는 다른 문제가 발생하더라도 주문 정보는 지속되어야 하며, 고객이 주문을 확인할 수 있어야 한다. 데이터베이스 트랜잭션의 특성을 나타내는 약어로 Atomicity(원자성), Consistency(일관성), Isolation(고립성), Durability(지속성)을 나타낸다.
- 원자성 (Atomicity):
-
격리성을 완벽하게 보장하기 위해서는
트랜잭션을 순서대로 실행할 수 있지만 이렇게 동작할 경우 동시처리 성능이 나빠진다.
트랜잭션은 기본적으로 동시에 여러 개가 실행될 수 있다.
격리 수준은 이러한 동시성에서 발생할 수 있는 문제들을 어떻게 제어할 것인지를 정의한다.
즉,트랜잭션 격리 수준은 여러 트랜잭션이 동시에 실행될 때, 특정 트랜잭션이 다른 트랜잭션에서 데이터를 변경하거나 조회할지 등 간섭할지 여부를 제어하는데 사용된다. 이처럼 격리 수준은 트랜잭션 간의 데이터 일관성을 유지하기 위해 중요하다.
<트랜잭션 격리 수준 Isolation level>
- READ UNCOMMITTED (커밋되지 않은 읽기):
- 다른 트랜잭션이 커밋되지 않은 데이터를 읽을 수 있다. 이로 인해 Dirty Read(더티 리드), Non-Repeatable Read(반복 불가능한 읽기) 등의 문제가 발생할 수 있다.
- 활용 예시: 실시간 보고서 생성 시에 최신 데이터를 빠르게 반영하고자 할 때 사용될 수 있다.
- Dirty Read(더티 리드)는 다른 트랜잭션이 아직 커밋되지 않은 데이터를 읽는 현상을 말한다. 트랜잭션이 데이터를 변경하고 커밋하기 전에 다른 트랜잭션이 해당 데이터를 읽으면, 그 읽힌 데이터는 커밋되지 않아 롤백될 수 있으므로 정확하지 않거나 무의미한 데이터가 될 수 있다.
- 트랜잭션 격리 수준이 READ COMMITTED 이상으로 설정되면 Dirty Read 문제를 방지할 수 있다. READ COMMITTED 이상의 격리 수준에서는 다른 트랜잭션이 아직 커밋되지 않은 데이터를 읽지 못하도록 보장되기 때문이다.
- 다른 트랜잭션이 커밋되지 않은 데이터를 읽을 수 있다. 이로 인해 Dirty Read(더티 리드), Non-Repeatable Read(반복 불가능한 읽기) 등의 문제가 발생할 수 있다.
- READ COMMITTED (커밋된 읽기):
- 커밋된 데이터만 읽을 수 있다. 다른 트랜잭션이 작업을 커밋하기 전까지 데이터를 읽을 수 없어 Dirty Read는 발생하지 않지만, Non-Repeatable Read 문제가 발생할 수 있다.
- 활용 예시: 데이터베이스의 무결성을 중시하는 경우에 사용될 수 있습니다.
- Non-Repeatable Read : 트랜잭션이 동일한 쿼리를 수행했을 때, 두 번째 읽기에서 다른 값을 반환하는 문제를 가리킨다. 이는 동일한 트랜잭션 안에서 동일한 데이터를 읽을 때 일관성이 유지되지 않는 상황을 말한다.
- 트랜잭션 A:
- 시작 시점에 데이터 X를 읽습니다. (값: 100)
- 트랜잭션 B:
- 트랜잭션 A가 진행 중일 때, 데이터 X를 수정하고 커밋합니다. (값: 200)
- 트랜잭션 A:
- 이어서 동일한 데이터 X를 다시 읽으려고 합니다.
- Non-Repeatable Read 문제: 이전에 읽은 값과 다르게 새로운 값 (200)를 읽게 됩니다.
- 트랜잭션 A:
- 이렇게 트랜잭션이 같은 데이터를 두 번 이상 읽을 때, 중간에 다른 트랜잭션이 해당 데이터를 수정하고 커밋하면서 값이 변경되어 버리는 현상이 발생한다.이러한 상황에서는 트랜잭션 내에서 일관성이 깨지게 되어 Non-Repeatable Read 문제가 발생합니다.
- 트랜잭션 격리 수준이 REPEATABLE READ 이상으로 설정되면 Non-Repeatable Read 문제는 방지된다. REPEATABLE READ 이상의 격리 수준에서는 동일한 트랜잭션 안에서 같은 데이터를 여러 번 읽어도 그 값이 변경되지 않음이 보장된다.
- 커밋된 데이터만 읽을 수 있다. 다른 트랜잭션이 작업을 커밋하기 전까지 데이터를 읽을 수 없어 Dirty Read는 발생하지 않지만, Non-Repeatable Read 문제가 발생할 수 있다.
- REPEATABLE READ (반복 가능한 읽기):
- 동일한 쿼리를 여러 번 실행해도 항상 동일한 결과를 보장한다. 다른 트랜잭션이 해당 범위의 데이터를 변경할 수 없도록 하지만 새로운 레코드가 추가되는 경우에 부정합이 생길 수 있다.
- 활용 예시: 일정 시간 동안 동일한 데이터를 여러 번 읽어야 하는 작업에서 사용될 수 있습니다.
- REPEATABLE READ는 트랜잭션 번호를 참고하여 자신보다 먼저 실행된 트랜잭션의 데이터만을 조회한다. 만약 테이블에 자신보다 이후에 실행된 트랜잭션의 데이터가 존재한다면 언두 로그를 참고해서 데이터를 조회한다.
- SERIALIZABLE (직렬화 가능):
- 트랜잭션 간에 완전한 격리를 보장한다. 다른 트랜잭션이 해당 범위의 데이터에 접근하지 못하도록 막아주어 가장 엄격한 격리 수준이지만, 접근하지 못해 트랜잭션이 순차적으로 실행되어야하기 때문에 동시성이 낮아질 수 있다. 가장 안전하고 가장 성능이 떨어진다.
- 활용 예시: 데이터 정합성이 최우선이 되는 금융 거래와 같이 매우 중요한 트랜잭션에서 사용될 수 있다.
트랜잭션이 동작하기 위해 필요한 것
0. 자동커밋이 아닌 수동 커밋이어야 한다.
- 자동커밋은 set autocommit true; 각각의 쿼리 실행 직후에 자동으로 커밋호출된다. 바로 데이터베이스에 반영되어 우리가 원하는 트랜잭션 기능을 제대로 사용할 수 없다.
- 수동 커밋 은 set autocommit false; 수동 커밋 모드로 설정하는 것을 트랜잭션을 시작한다고 표현한다.
1. DB 서버에 연결하기 위한 커넥션이 필요하다.
커넥션을 생성해 맺고
2. DB서버는 내부 세션을 만든다.
3. 커넥션을 통한 모든 요청이 이 세션을 통해 실행하게 된다.
4. 세션은 트랜잭션을 시작하고 , 커밋 또는 롤백을 통해 트랜잭션을 종료한다.
5. 사용자가 커넥션을 닫거나 DBA(데이터 베이스 관리자)가 세션을 강제로 종료하면 세션은 종료된다.
커넥션 풀이 10개의 커넥션을 생성하면 세션도 10개 만들어진다.
커밋을 호출하기 전까지는 임시로 데이터를 저장하는 것이므로
해당 트랜잭션을 시작한 세션에서만 변경 데이터가 보이고 다른 세션에서는 변경데이터가 보이지 않는다.
커밋하기 전에 롤백을 하면 직전 상태로 복구된다.
<락 사용>
세션 1이 트랜잭션 시작하고 데이터를 수정하는 동안 아직 커밋하지 않았는데
세션2에서 동시에 같은 데이터를 수정하게 되면 문제가 발생한다.
이를 방지하기 위해 커밋이나 롤백전까지 다른 세션에서 해당 데이터를 수정할 수 없게 락 개념이 사용된다.
락을 획득해서 커밋후에 락을 반납하기까지 다른 세션에서는 락을 획득하기 위해서 대기하는 방식이다. 설정된 락 타임아웃 시간보다 더 오래 대기하면 락 타임아웃 오류가 발생한다.
조회시에 보통 락 획득하지 않고 바로 데이터를 조회할 수 있지만 조회시에도 락을 획득하고 싶다면 select for update구문을 사용하면 된다. 이렇게 되면 특정 세션이 조회할 때 락을 가져가 버리기 때문에 해당 데이터를 다른 세션에서 변경할 수 없다.
- 조회시점에 락 필요한 경우
- 예) 금액 조회하고 그 금액 정보로 다른 계산을 수행해야할 때
<트랜잭션을 어디에서 시작하고 어디에서 커밋해야하는가?>
트랜잭션은 비즈니스 로직이 있는 서비스 계층에서 시작해야한다. 로직이 잘못되었을 시 롤백하기 위해서이다. 하지만 트랜잭션을 시작하기 위해서는 커넥션이 필요하다. 커넥션만들고 트랜잭션 커밋, 커넥션 종료까지 해야한다.
또한 같은 세션에서 작업하기 위해 같은 케넥션을 유지해아한다.
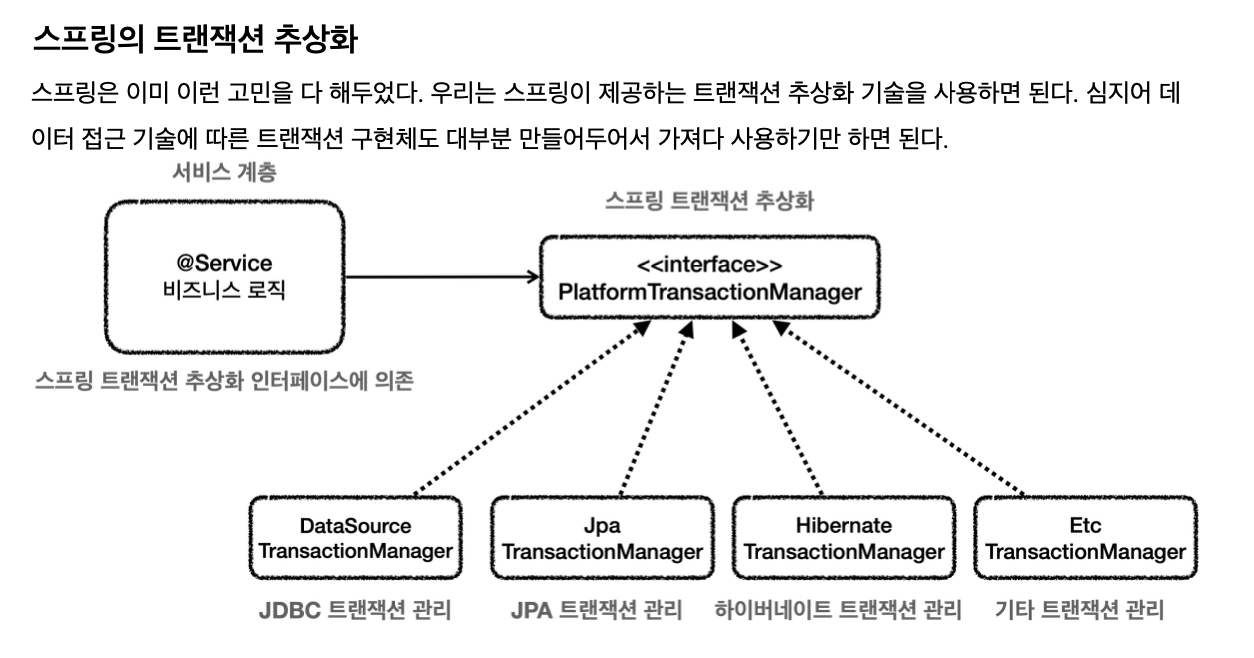
스프링 트랜잭션이 가져다주는 편리함은 무엇일까?
스프링이 제공하는 트랜잭션 매니저는
1. 추상화


package org.springframework.transaction;
public interface PlatformTransactionManager extends TransactionManager {
TransactionStatus getTransaction(@Nullable TransactionDefinition definition)
throws TransactionException;
void commit(TransactionStatus status) throws TransactionException;
void rollback(TransactionStatus status) throws TransactionException;
}
추상화된 트랜잭션 매니저 인터페이스를 통해
코드를 변경하지 않고
다양한 데이터 접근 기술을 사용할 수 있다.
2. 리소스 동기화
- 트랜잭션을 유지하기 위해서는 같은 데이터베이스 커넥션을 유지해야한다.
- 파라미터로 커넥션을 전달하는 것 대신 트랜잭션 동기화 매니저를 사용한다!
PlatformTransactionManager과 같은 트랜잭션 매니저는 트랜잭션이 시작된 커넥션을 트랜잭션 동기화 매니저에 보관한다.
리포지토리는 트랜잭션 동기화 매니저에 보관된 커넥션을 꺼내서 사용한다.
트랜잭션이 종료되면 트랜잭션 매니저는 트랜잭션 동기화 매니저에 보관된 커넥션을 통해 트랜잭션을 종료하고 커넥션도 닫는다.
트랜잭션 동기화 매니저를 보면

쓰레드 로컬을 사용하는 것을 확인할 수 있다.
쓰레드 로컬을 사용해서 각각의 쓰레드마다 별도의 저장소가 부여되어 해당 쓰레드만 해당 데이터에 접근할 수 있게 하여 커넥션을 동기화 해준다.
내부 코드를 보면 자원을 맵으로 저장하고 가져오고 확인하는 로직이 있다
public static Map<Object, Object> getResourceMap() {
Map<Object, Object> map = resources.get();
return (map != null ? Collections.unmodifiableMap(map) : Collections.emptyMap());
}
/**
* Check if there is a resource for the given key bound to the current thread.
* @param key the key to check (usually the resource factory)
* @return if there is a value bound to the current thread
* @see ResourceTransactionManager#getResourceFactory()
*/
public static boolean hasResource(Object key) {
Object actualKey = TransactionSynchronizationUtils.unwrapResourceIfNecessary(key);
Object value = doGetResource(actualKey);
return (value != null);
}
/**
* Retrieve a resource for the given key that is bound to the current thread.
* @param key the key to check (usually the resource factory)
* @return a value bound to the current thread (usually the active
* resource object), or {@code null} if none
* @see ResourceTransactionManager#getResourceFactory()
*/
@Nullable
public static Object getResource(Object key) {
Object actualKey = TransactionSynchronizationUtils.unwrapResourceIfNecessary(key);
return doGetResource(actualKey);
}
...
스프링이 제공하는 트랜잭션 매니저를 다시 정리해보면

트랜잭션 시작1
- 서비스 계층에서 transactionManager.getTransaction() 를 호출해서 트랜잭션 시작하면
- 트랜잭션 시작하기 위해서 트랜잭션 매니저가 내부에서 DataSource를 사용해 커넥션을 생성
- 커넥션을 수동 커밋모드로 변경해서 실제 DB트랜잭션 시작
- 커넥션을 트랜잭션 동기화 매니저에 보관
- 트랜잭션 동기화 매니저는 쓰레드 로컬에 커넥션을 보관! 이로써 멀티 쓰레드 환경에서 안전하게 보관할 수 있다.

트랜잭션 시작2
- 서비스는 비즈니스 로직을 실행하면서 리포지토리의 메서드들을 호출한다.
- 리포지토리 메서드들은 트랜잭션이 시작된 커넥션이 필요해서 DataSourceUtils.getConnection() 를 사용해 트랜잭션 동기화 매니저에 보관된 커넥션을 꺼내 사용한다. 이로써 같은 커넥션을 사용하고 트랜잭션도 유지된다.
- 획득한 커넥션을 사용해서 SQL을 DB에 전달해서 실행한다.
리포지토리(Repository)는 데이터베이스와 관련된 작업을 수행하는 객체로, 주로 데이터베이스와의 상호작용을 추상화하고 데이터 액세스를 담당한다.
예를 들어, 스프링 프레임워크에서는 JPA(Java Persistence API)나 Hibernate와 같은 ORM(Object-Relational Mapping) 기술을 사용할 때 리포지토리를 자주 사용한다. 이를 통해 데이터베이스와의 통신을 추상화하고, 개발자는 객체 지향적인 방식으로 데이터베이스와 상호작용할 수 있다.
트랜잭션 종료3
- 비즈니스 로직 끝나고 트랜잭션을 종료한다. 트랜잭션은 커밋하거나 롤백하면 종료된다
- 트랜잭션을 종료하려면 동기화된 커넥션이 필요하다. 트랜잭션 동기화 매니저를 통해 동기화된 커넥션을 획득한다
- 획득한 커넥션 통해 데이터베이스에 트랜잭션을 커밋하거나 롤백한다.
- 전체 리소스 정리한다.
- 트랜잭션 동기화 매니저 정리. 쓰레드 로컬은 사용 후 꼭 정리해야한다.
- 자동커밋 true로 되돌린다. 커넥션풀을 고려!
- close호출해 커넥션 종료! 커넥션 풀 사용했을시에는 종료하면 커넥션 풀에 반환된다.
TransactionTemplate 템플릿은
반복되는 성공시 커밋, 롤백 코드를 깔끔하게 해결하고 비즈니스 로직만 남도록 한다.
이 경우, 비즈니스 로직이 정상수행 되면 커밋하고
언체크 예외 발생하면 롤백한다. 그 외에 경우 커밋한다.
서비스 로직에 비즈니스 로직만 담고 트랜잭션 기술을 처리하는 코드는 없애기 위해서
스프링 AOP를 통해 프록시를 도입했다
프록시를 사용하면 트랜잭션을 처리하는 객체와 비즈니스 로직을 처리하는 서비스 객체를 명확하게 분리할 수 있다.

스프링이 제공하는 트랜잭션 AOP기능을 사용하면 프록시를 편하게 사용할 수 있다.
다음 시간에 트랜잭션 AOP에 대해 공부하고 정리해보자.
'스프링' 카테고리의 다른 글
| 코드 리팩토링과 ExceptionHandler를 이용한 전역예외처리 (bindingresult도 잡기!) (1) | 2024.01.25 |
|---|---|
| 에러핸들링, 예외처리 어떻게 할까? (1) | 2023.12.21 |
| 강의) 스프링 MVC 1편 - 백엔드 웹 개발 핵심 기술 (0) | 2023.12.05 |
| 강의) 스프링 핵심 원리 - 기본편 (0) | 2023.12.05 |
| 책) 스프링 입문을 위한 자바 객체지향원리와 원리 (0) | 2023.12.05 |
























































































































