https://leetcode.com/problems/concatenation-of-consecutive-binary-numbers/description/
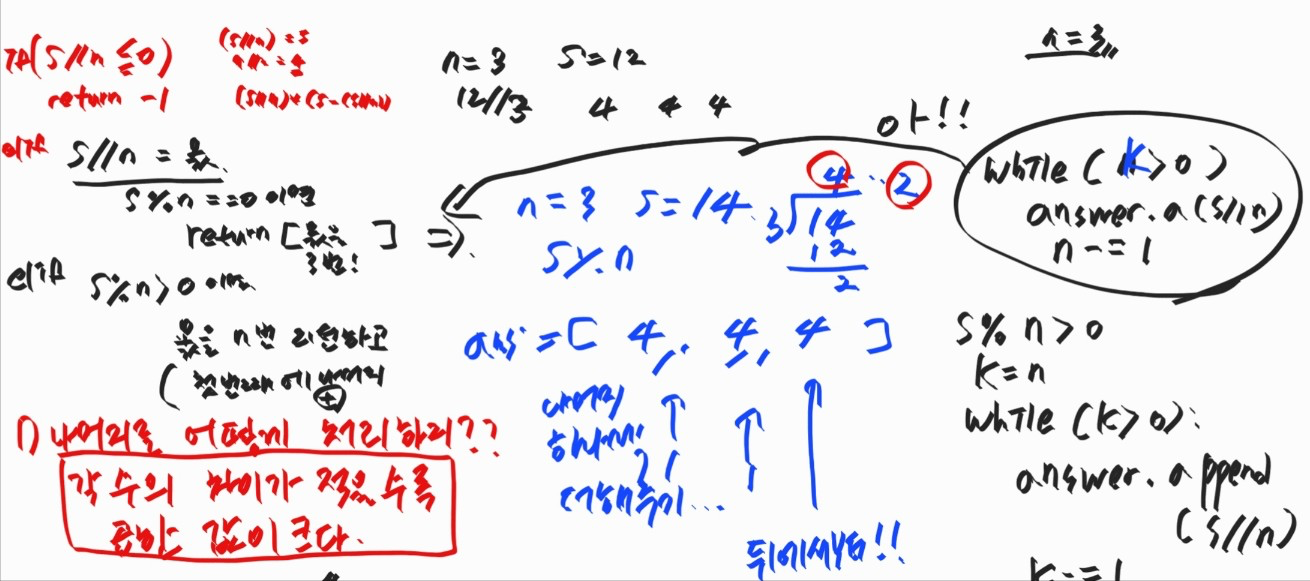
주어진 n의 값을 연속적으로 이진법으로 만들고
그 값을 다시 10진법으로 만들어 구하는 문제
최종 코드
n이 12일때
package 리트코드;
public class ConcatenationOfConsecutiveBinaryNumbers1680 {
private static final int MOD = 1000000007;
public int concatenatedBinary(int n) {
//long은 19자리수 가능
long result = 0;
for (int i = 1; i <= n; i++) {
int num = i;
StringBuilder binaryStr = new StringBuilder();
while (num > 0) {
binaryStr.append(num % 2); //나머지 넣기
num /= 2; //2나누기
}
binaryStr.reverse();
String binary = binaryStr.toString();
//비트 연산을 통해 이진 문자열을 추가
for (char c : binary.toCharArray()) {
//2로 곱하고 나머지를 더하는 식임
// '0'을 빼면 수로 변환됨
//MOD로 나눈 나머지로 구하는 이유는 매우큰 숫자 다룰 때 오버플로우 방지하고 결과를 적절한 범위내에서 유지하기 위함임
result = (result * 2 + (c - '0')) % MOD;
System.out.println("result = " + result);
}
}
return (int) result;
}
public static void main(String[] args) {
int n = 12;
ConcatenationOfConsecutiveBinaryNumbers1680 concatenationOfConsecutiveBinaryNumbers1680 = new ConcatenationOfConsecutiveBinaryNumbers1680();
int result = concatenationOfConsecutiveBinaryNumbers1680.concatenatedBinary(n);
System.out.println("result = " + result);
}
}
result = 1
result = 3
result = 6
result = 13
result = 27
result = 55
result = 110
result = 220
result = 441
result = 882
result = 1765
result = 3531
result = 7063
result = 14126
result = 28253
result = 56507
result = 113015
result = 226031
result = 452062
result = 904124
result = 1808248
result = 3616497
result = 7232994
result = 14465988
result = 28931977
result = 57863955
result = 115727910
result = 231455821
result = 462911642
result = 925823285 -> 여기까진 값네 925823285
result = 851646563 (-> 나누지 않은 값이 1851646570 = 925823285 *2 로, 10자리여서 MOD로 나눠지게 됨. 그 나머지값임)
result = 703293120
result = 406586234
result = 813172469
result = 626344932
result = 252689857
result = 505379714
result = 505379714
근데 만약 MOD를 나눈 나머지 값으로 구하지 않는다면?
private static final int MOD = 1000000007;
result = (result * 2 + (c - '0'));
result = 1
result = 3
result = 6
result = 13
result = 27
result = 55
result = 110
result = 220
result = 441
result = 882
result = 1765
result = 3531
result = 7063
result = 14126
result = 28253
result = 56507
result = 113015
result = 226031
result = 452062
result = 904124
result = 1808248
result = 3616497
result = 7232994
result = 14465988
result = 28931977
result = 57863955
result = 115727910
result = 231455821
result = 462911642
result = 925823285 -> 9자리
--여기까지 같음--
result = 1851646570 = 925823285 *2
result = 3703293141 = 1851646570 * 2 +(나머지 1 더함 )
result = 7406586283
result = 14813172567
result = 29626345135
result = 59252690270
result = 118505380540
result = -1753703748 = 118505380540 * 2 = 237,010,761,080
근데 long이 19자리수까지 가능한데도 굳이 MOD를 나누는 이유는
수의 크기가 너무 커져서 오버플로우가 일어나는 것을 방지하기 위함.
MOD 상수값을 나누고 그 나머지로 사용한다는
문제의 조건이었음!!
'코딩테스트 > 릿코드' 카테고리의 다른 글
| 릿코드 875. Koko Eating Bananas 바이너리 서치 (0) | 2023.08.31 |
|---|